TL;DR. We improve out-of-distribution language generalization of continuous-action VLA policies
through action expert pretraining. Guided by a Bayesian factorization
\(\pi(\mathbf{a}\mid\mathbf{v},\ell)\propto\pi^{p}(\mathbf{a}\mid\mathbf{v})\,L(\ell\mid\mathbf{v},\mathbf{a})\),
we first pretrain the action expert as a language-agnostic Vision-Action (VA) prior
\(\pi^{p}(\mathbf{a}\mid\mathbf{v})\), then inject language to form the VLA likelihood.
Abstract
Vision-Language-Action (VLA) models that couple pretrained VLMs with continuous action experts
achieve strong manipulation, yet generalize poorly to out-of-distribution (OOD) language
instructions. The cause is a structural imbalance in VLA data — language is far less diverse
than visual and action content — which biases policies toward visual shortcuts. Unlike
discrete-action methods protected by vision-language co-training, continuous action experts learn
from scratch on this imbalanced data, producing noisy gradients that corrupt the VLM. From a Bayesian
perspective, we factorize the policy into a language-agnostic Vision-Action (VA) prior and a
language-conditioned VLA likelihood, and propose APT, a two-stage method emphasizing
Action expert PreTraining: Stage 1 pretrains the action expert as a VA prior on
vision-action pairs from a frozen VLM, bypassing the language imbalance; Stage 2 injects language
through a gated fusion mechanism that preserves the learned visuomotor prior. APT applies to
mainstream VLA architectures (π- and GR00T-style) and consistently improves generalization to
unseen instructions and compositional tasks.
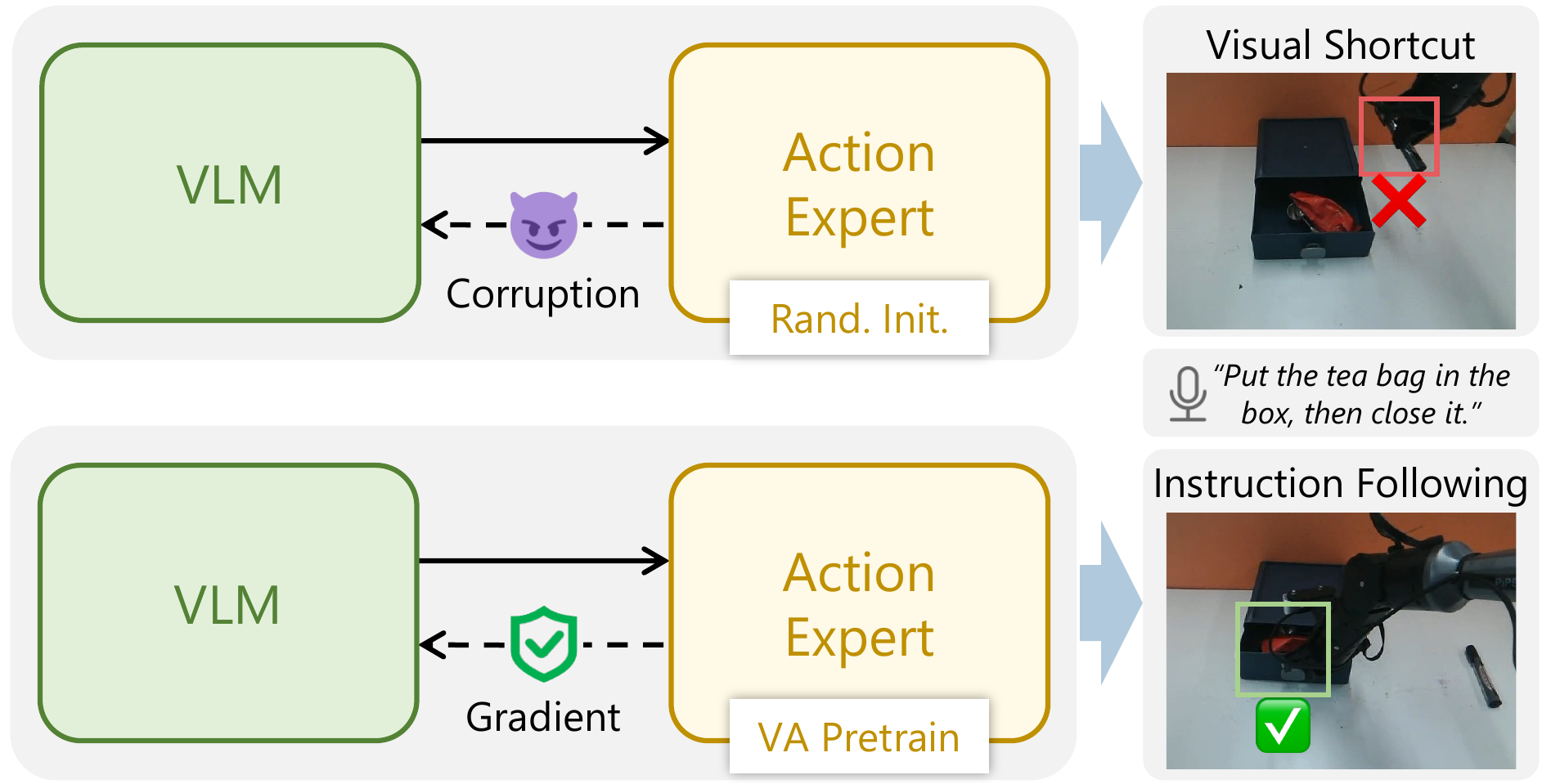
A randomly initialized action expert gravitates toward visual shortcuts and produces noisy
gradients that corrupt the VLM. Pretraining the action expert as a VA prior (VA Pretrain)
instead yields clean gradients and enables effective instruction following.
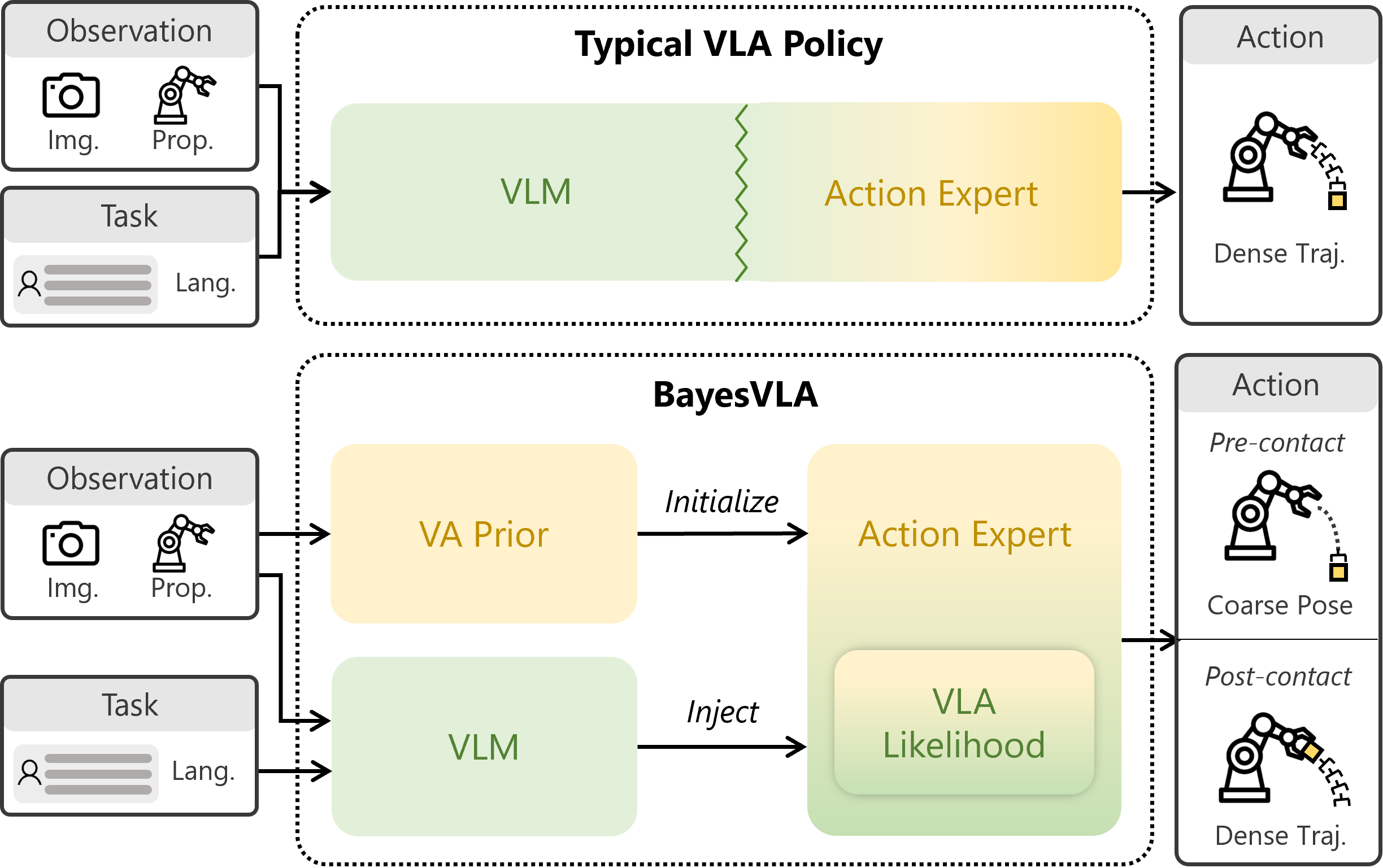
Method
We factorize the VLA policy from a Bayesian perspective, separating action generation into a
language-agnostic Vision-Action (VA) prior \(\pi^{p}(\mathbf{a}\mid\mathbf{v})\) and a
language-conditioned VLA likelihood \(L(\ell\mid\mathbf{v},\mathbf{a})\). The key observation is that
although full VLA triplets suffer from language-vision imbalance, vision-action pairs alone are
well-balanced and create no shortcut incentive.
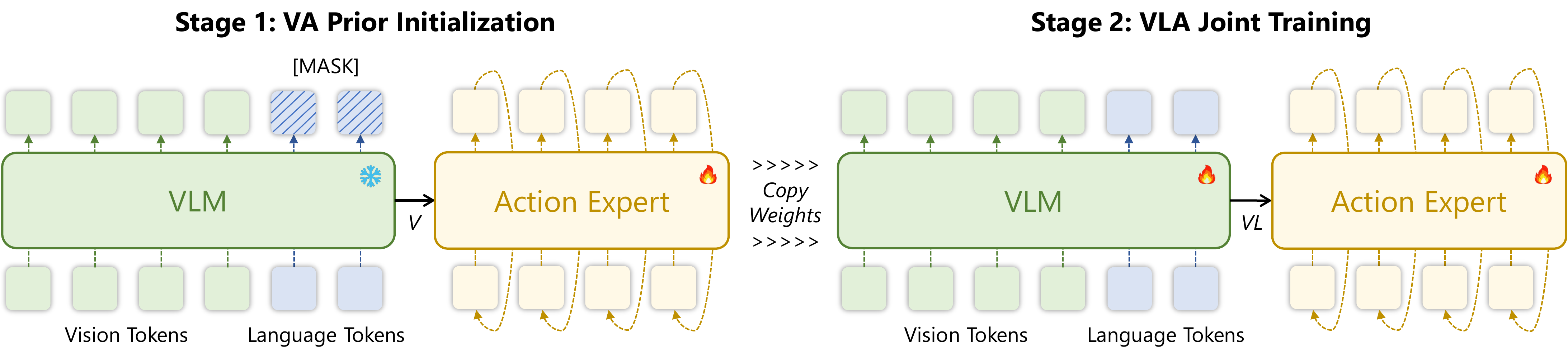
Stage 1 — VA Prior. A diffusion-based action expert is pretrained as a VA prior conditioned
solely on visual tokens from a frozen VLM backbone, with language tokens masked from all
self-attention computations — bypassing the language imbalance and providing a principled
initialization before any language is introduced.
Stage 2 — VLA Likelihood. Language tokens are injected through newly introduced interleaved
attention layers, and all layers are jointly finetuned starting from the Stage 1 checkpoint. A novel
action expert design with a layer-wise gated fusion mechanism integrates VLM features into the
action expert, inheriting the VLM's representational capacity while preserving the pretrained
visuomotor prior. The two-stage scheme applies to mainstream continuous-action VLA architectures,
such as the π- and GR00T-style architectures.
Overview of APT.Stage 1 (VA Prior Initialization): the action expert is pretrained on
vision tokens from a frozen VLM, with language tokens masked. Stage 2 (VLA Joint Training): the
learned weights are copied, language tokens are injected, and the VLM and action expert are jointly
finetuned.
Simulation Results
Quantitative Results
Method
Spatial
Object
Goal
Long
Avg
Pos
Task
Pos
Task
Pos
Task
Pos
Task
OpenVLA
0
0
0
0
0
0
0
0
0
π0
0
0
0
0
0
0
0
0
0
π0.5
20
1
17
1
38
0
8
1
11
LangForce
11
48
10
10
4
11
2
15
14
CaP-X
12
14
22
18
26
17
–
–
–
APT
44
48
7
10
23
11
6
3
19
APT (Ft VLM)
62
62
24
17
10
20
12
12
27
Table 1: Results on LIBERO-PRO (success rate %). Pos perturbs object positions; Task replaces the manipulated object for OOD language generalization.
Method
KI
2-Stage
Ft VLM
SO
UO
UC
UOleiUE
π0
–
–
✓
42
30
26
16
π0.5
✓
–
✓
84
70
86
50
APT
–
–
✓
88
56
66
34
✓
–
–
90
58
40
40
✓
✓
–
96
74
90
62
–
✓
✓
98
84
92
58
Table 2: Results on Rigid Object Pick-Place (success rate %). All four APT rows are trained solely on VLA data and ablate three dimensions — KI: Knowledge Insulation, 2-Stage: action expert pretraining, Ft VLM: joint VLM finetuning. SO: Seen Object, UO: Unseen Object, UC: Unseen Container, UE: Unseen Environment.
Qualitative Rollouts — Rigid Object Pick-Place
Test settings of increasing OOD difficulty: Seen Object (SO), Unseen Object (UO), Unseen Container (UC), Unseen Object & Unseen Environment (UOUE).
SO“Move the blue Pepsi to the bowl.”
\( \pi_{0.5} \)🙂 Success
APT (Ours)🙂 Success
UO“Move the orange bottle to the bowl.”
\( \pi_{0.5} \)🙁 Failure
APT (Ours)🙂 Success
UC“Move the black Pepsi to the mug.”
\( \pi_{0.5} \)🙁 Failure
APT (Ours)🙂 Success
UOUE“Move the blue can to the bowl.”
\( \pi_{0.5} \)🙁 Failure
APT (Ours)🙂 Success
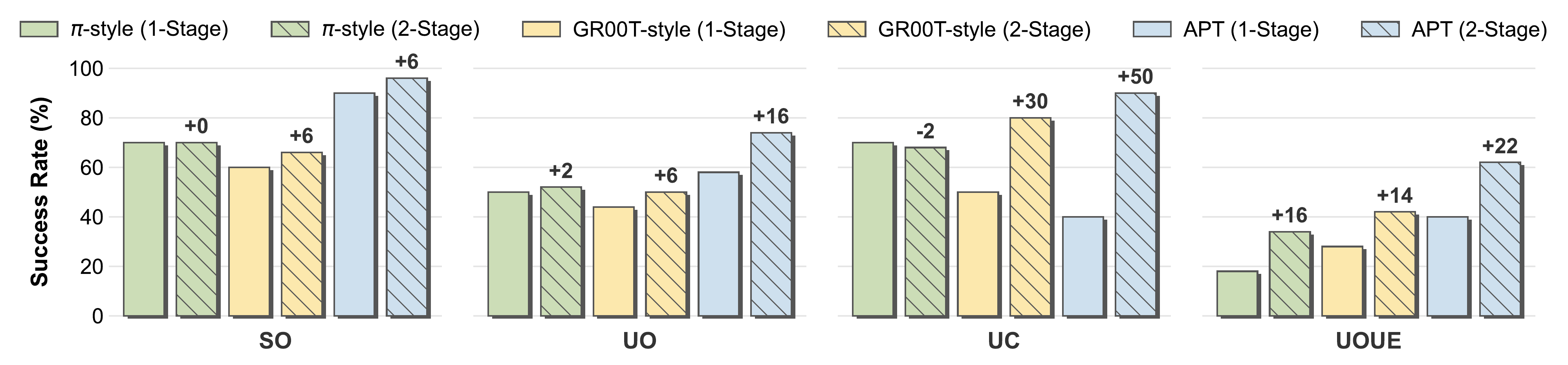
Architecture Generalization
Action expert pretraining applies to diverse architectures. The two-stage scheme improves
generalization across almost all settings, with the largest gains on APT and GR00T-style backbones;
labels denote the success-rate gain of 2-Stage over 1-Stage.
Real-World Results
Single Task Generalization
OOD language and object generalization within individual tasks.
Method
Pick-Place
Clutter Pick-Place
SO
UO
UOUC
UOUCUE
SO
UC
UO
UOUE
π0.5
27/30
11/20
9/20
16/40
18/30
18/30
4/10
3/10
APT
29/30
17/20
16/20
28/40
25/30
22/30
7/10
6/10
Table 3: Real-world single-task generalization results (successes / trials). 30 demonstrations per task; APT is compared against π0.5.
Pick-Place Pick a specified object and place it on a specified container, under unseen objects (UO), unseen containers (UC), and unseen environments (UE).
UOUC“Pick up the grape and place it on the drawer.”
\( \pi_{0.5} \)🙁 Failure
APT (Ours)🙂 Success
UOUCUE“Pick up the grape and place it on the drawer.”
\( \pi_{0.5} \)🙁 Failure
APT (Ours)🙂 Success
Clutter Pick-Place Pick-and-place amid cluttered distractor objects, under seen objects (SO), unseen objects (UO), and unseen environments (UE).
SO“Pick up the pepper and place it on the blue plate.”
\( \pi_{0.5} \)🙁 Failure
APT (Ours)🙂 Success
UOUE“Pick up the grape and place it on the pink plate.”
\( \pi_{0.5} \)🙁 Failure
APT (Ours)🙂 Success
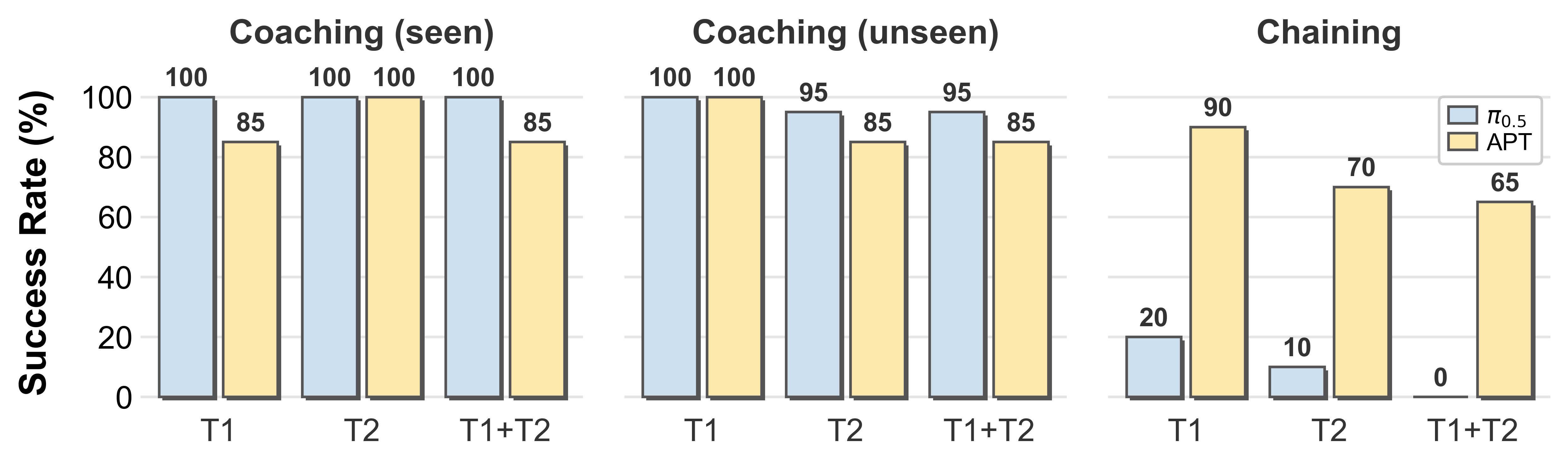
Compositional Task Generalization
Sequential multi-task instruction following, via task coaching (per-task instructions issued in sequence) and task chaining (a single concatenated instruction).
Success rate on compositional tasks for the first task (T1), second task (T2), and the full sequence (T1+T2). APT degrades far less than \( \pi_{0.5} \) under task chaining, where a single instruction must be parsed into multiple subtasks.
Coaching Per-task instructions issued in sequence.
Example 1“(1) Put the red tea bag into the box, then close the storage box. (2) Pick up the pepper and place it on the blue plate.”
\( \pi_{0.5} \)🙁 Failure
APT (Ours)🙂 Success
Example 2“(1) Put the pepper into the box, then close the storage box. (2) Pick up the red tea bag and place it on the blue plate.”
\( \pi_{0.5} \)🙁 Failure
APT (Ours)🙂 Success
Chaining A single concatenated instruction.
✨
Highlight. Task chaining is the hardest test of compositional generalization — a
single instruction must be parsed into multiple sequential subtasks with no per-step prompting.
On the full sequence (T1+T2), \( \pi_{0.5} \) collapses to 0%, while APT
reaches 65% (and 90% / 70%
on the individual subtasks), demonstrating compositional instruction following beyond what existing
open-source VLA policies achieve.
Example 1“Put the red tea bag into the box. Then close the storage box. Pick up the pepper and place it on the blue plate.”
\( \pi_{0.5} \)🙁 Failure
APT (Ours)🙂 Success
Example 2“Put the red tea bag into the storage box. Then close the box. Pick up the carrot and place it on the blue plate.”
@article{xu2026apt,
title = {APT: Action Expert Pretraining Improves Instruction Generalization of Vision-Language-Action Policies},
author = {Xu, Kechun and Zhu, Zhenjie and Chen, Anzhe and Xiong, Rong and Wang, Yue},
journal = {arXiv preprint arXiv:XXXX.XXXXX},
year = {2026}
}